
Multi-Agent Systems Architecture: The Real Job Behind OKX's AI Platform Hire
Most companies talking about "AI agents" right now are demoing one. A single model with a few tools, wired up in a weekend, doing something impressive on a stage. That's a prototype. It is not what OKX is hiring for.
In June 2026, one of the top three crypto exchanges by volume posted a role called AI Native Platform Architect. Read the requirements and the gap between the demo and the job becomes obvious. Eight-plus years of engineering. Java and Python. LangChain and LangGraph. RAG and GraphRAG. Kubernetes. Task decomposition, multi-agent system design, governance frameworks, SDLC automation across teams. Nobody writes that job description to build a chatbot. OKX is hiring someone to run a fleet of AI agents in production, at exchange scale, with an audit trail — and that is a fundamentally different discipline than using an LLM.
This is multi-agent systems architecture, and it's quietly becoming one of the most demanding engineering roles in web3. Here's what it actually involves, why an exchange is building this layer now, and what kind of experience qualifies you for it.
What Is Multi-Agent Systems Architecture?
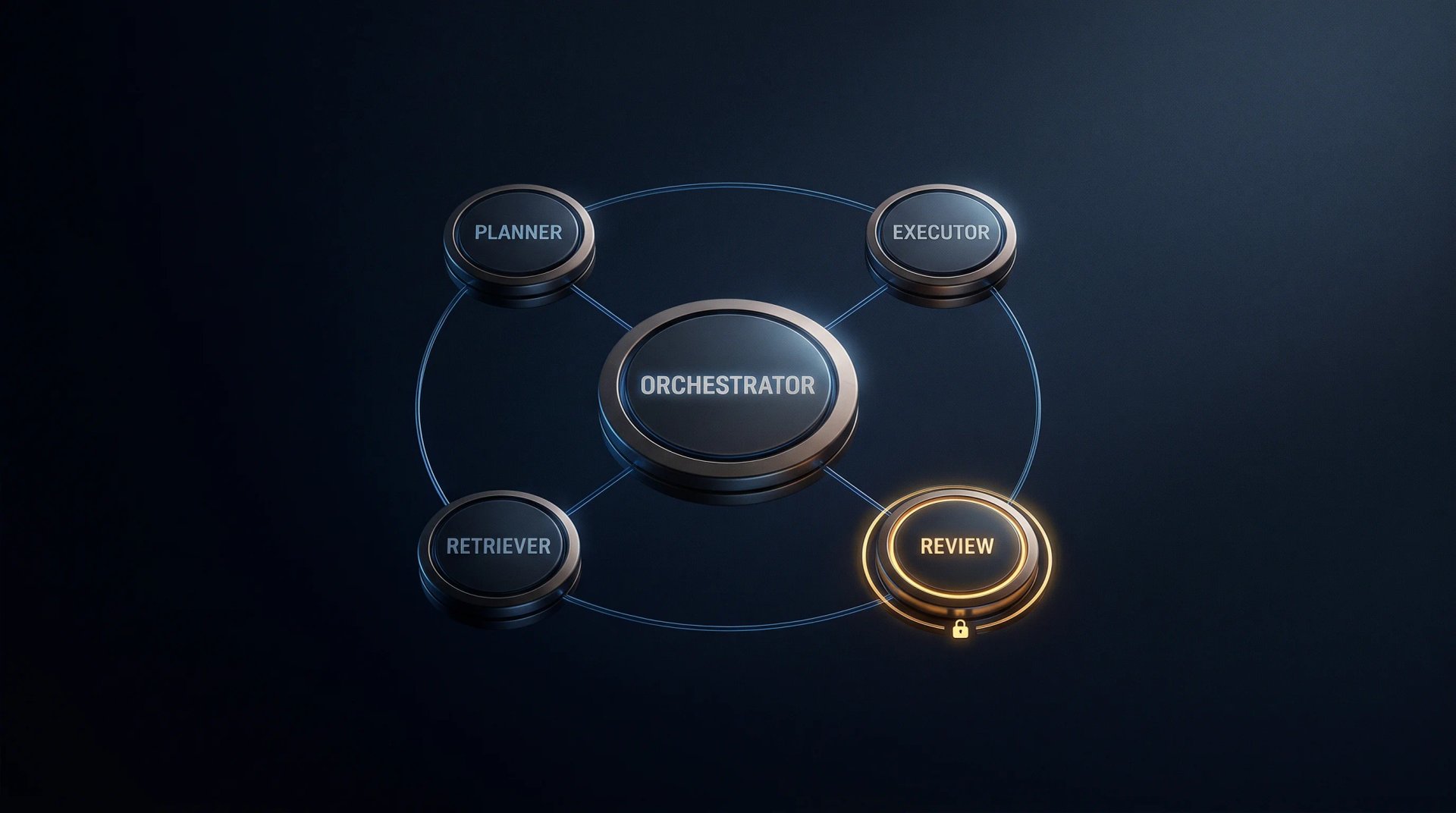
Multi-agent systems architecture is the discipline of designing, deploying, and governing systems where multiple AI agents — each with a defined role — collaborate to accomplish tasks that no single model or process could handle alone. It's the layer above "calling an LLM." You're building the orchestration, the shared memory, the inter-agent protocols, and the governance that lets a network of agents do real work without quietly going off the rails.
A useful way to picture it: instead of one model trying to do everything, you have specialists. A planning agent decomposes a task. Executor agents handle the sub-tasks. A retrieval agent pulls relevant internal context — code patterns, security policies, prior decisions — from a knowledge layer. A review agent checks the outputs before anything ships. An orchestrator routes work between them and decides what to do when one of them fails. A human approves the calls that matter.
The hard part isn't getting that to work once. It's getting it to work reliably, ten thousand times a day, on infrastructure you'd trust with an exchange's codebase.
Why an Exchange Builds This Layer First
You might expect AI labs to lead here. In practice, crypto exchanges have a sharper incentive. Their engineering throughput is the business. The faster and more safely they ship, the more product surface they cover against Binance, Bybit, and Coinbase. When your competitive moat is partly developer velocity, a platform that automates the grind of software delivery is not a side project — it's a direct lever on how fast the company moves.
That's why OKX's role centers on SDLC automation: code review, test generation, documentation, deployment checks, PR triage. These are the high-volume, judgment-light tasks that eat senior engineers' time. Hand them to a network of agents and your humans spend their hours on architecture and the genuinely hard calls. That math gets compelling fast at an organization with thousands of engineers.
There's a second signal buried in the requirements, and it's the one most people skim past. OKX asked for GraphRAG, not just RAG. That's a deliberate choice. Standard retrieval pulls relevant documents and stuffs them into context. GraphRAG builds a knowledge graph over your proprietary data — the relationships between services, the history of why a system was built a certain way, the dependencies that aren't written down anywhere. You don't reach for GraphRAG to answer questions about external docs. You reach for it when you're trying to give agents real institutional memory about your own systems. That tells you OKX isn't bolting AI onto the edges. They're building it a model of how the company actually works.
What the Job Actually Requires
The OKX listing maps to four distinct capabilities, and almost nobody has all four cold. That's the whole reason the experience bar is eight-plus years.
1. Distributed systems engineering, not ML research. Notice what's not in the requirements: no PhD, no model training, no research publications. The stack is Java, Python, Kubernetes. This is a backend platform role. The agents are the workload; the job is making that workload reliable, observable, and scalable. If you've run production systems where things fail at 3am and you're the one who designed for that, you already have the foundation. The LLM part is learnable. The "keep a distributed system honest under load" part is the decade.
2. Orchestration with LangGraph and friends. LangChain got you the building blocks. LangGraph is where you express agent workflows as stateful graphs — branching, looping, retrying, handing context between agents without losing the thread. Building this in production means handling partial failures, preventing one agent's hallucination from cascading into the next, and keeping latency sane when a task fans out across five models. It's closer to designing a workflow engine than to prompt-tweaking.
3. A knowledge layer that's actually correct. GraphRAG is powerful and unforgiving. A knowledge graph over your codebase is only as good as its freshness and accuracy — feed agents stale or wrong context and they'll make confident, wrong decisions at scale. So a real chunk of this job is data engineering: building the pipelines that keep the graph current, deciding what's worth indexing, and designing retrieval that surfaces the right context instead of the most superficially similar.
4. Governance, which is the part that separates the architect from the tinkerer. This is the requirement that should reframe how you read the whole role. Who can authorize an agent to merge code? How do you audit a decision a network of agents made collaboratively? How do you roll back when an agent chain produces a bad outcome? What's the blast radius when something goes wrong? At a regulated exchange, "the AI did it" is not an acceptable answer to a regulator or a post-mortem. Governance — authorization, auditability, rollback, human checkpoints — is not paperwork bolted on at the end. It's the architecture.
The first three get you a working system. The fourth is what makes it safe to run on infrastructure that moves billions of dollars.
The Prototype-to-Production Gap
Here's the uncomfortable truth most "AI agent" content avoids: the distance between a demo that works and a system you'd run in production is enormous, and it's almost entirely the unglamorous part.
A demo agent that's right 85% of the time looks magical. A production agent that's right 85% of the time is a liability — because the 15% compounds. Chain four agents at 85% each and your end-to-end reliability is roughly 52%. The architect's job is to design the system so that errors get caught and contained rather than propagated: review agents that flag low-confidence outputs, human checkpoints at the decisions that matter, and orchestration that fails closed instead of open.
This is why the role asks for someone who's productionized systems before, not someone who's read about agents. The interesting engineering isn't making agents do the work. It's designing for the moment they get it wrong — because at scale, they will, and the architecture is what decides whether that's a logged exception or an incident.
How to Get There From Where You Are
If you're a senior backend or platform engineer: you are closer than you think, and probably underrating yourself. You have the distributed-systems instincts that are the genuinely scarce part. Your gap is the agent layer — go build something real with LangGraph, wire up a retrieval layer, and feel where it breaks under failure. Don't start by learning to train models. You almost certainly won't need to. Start by treating agents as an unreliable distributed component and applying everything you already know about making unreliable components safe.
If you're an ML or AI engineer: your model intuition is an asset, but the role isn't optimized for it. Most of this work is systems design, not modeling. Your highest-leverage move is to get fluent in production engineering — Kubernetes, observability, failure handling, the operational reality of running services. The architects who win these roles think like platform engineers who happen to understand models, not like researchers who happen to deploy.
If you're an engineering leader evaluating whether to build this: the OKX posting is your benchmark for seriousness. If your AI initiative doesn't have a governance story — authorization, audit, rollback — you don't have a platform, you have a pile of demos waiting to cause an incident. Hire for the distributed-systems and governance depth first. The agent tooling moves fast enough that betting on someone who can learn it beats betting on someone who memorized this year's framework.
The Broader Signal
OKX's hire is not an isolated event. It's the platform-engineering instance of the same pattern showing up across web3 right now. The same week, Serotonin posted an AI GTM Engineer to build the marketing function's AI layer. Ondo Finance posted a security engineer who has to build LLM-assisted triage and defend against AI-driven attacks. Different function, same move: the AI work isn't going to a separate AI team. It's being absorbed into the team that owns the domain.
For platform engineering, that absorption produces multi-agent systems architecture — the discipline of making fleets of agents reliable enough to trust with real work. It's demanding, it's scarce, and right now it's wide open. The engineers who can bridge distributed-systems rigor and agent orchestration won't be looking for jobs for long. The exchanges will be looking for them.
Frequently Asked Questions
What is multi-agent systems architecture in simple terms?
It's the engineering discipline of building systems where multiple specialized AI agents work together — one plans, others execute, one retrieves context, one reviews — coordinated by an orchestration layer with governance controls. Instead of a single model doing everything, you design a network of agents and the infrastructure that keeps them reliable, auditable, and safe in production. It's the difference between using an LLM and building AI infrastructure.
What skills do you need to be an AI platform architect?
Based on the OKX listing, the core requirements are: strong distributed-systems and backend engineering (Java/Python, Kubernetes), agent orchestration experience (LangChain/LangGraph), a knowledge-retrieval layer (RAG and increasingly GraphRAG), and governance design — authorization, auditability, and rollback for agent decisions. Notably, model training and ML research are not required. This is a production systems role, not a research role.
Do I need a machine learning background for this role?
Generally no. These roles ask for engineers who can build reliable production systems and integrate existing models, not researchers who train new ones. The OKX role lists no ML research requirement. A senior backend or platform engineer who learns the agent orchestration layer is closer to the target profile than an ML researcher who hasn't run production infrastructure.
What is the difference between RAG and GraphRAG?
Standard RAG retrieves relevant documents and adds them to a model's context at inference time. GraphRAG builds a knowledge graph that captures the relationships between entities — services, decisions, dependencies — and retrieves over that structure. GraphRAG is harder to build and maintain but gives agents a richer model of how a system actually fits together, which is why it shows up when companies want agents to reason about their own proprietary infrastructure rather than external documents.
Why are crypto exchanges hiring for multi-agent systems first?
Because engineering throughput is a direct competitive lever for an exchange, and AI-driven SDLC automation increases it. Exchanges also operate under regulatory scrutiny, which makes the governance and audit side of multi-agent systems a first-class requirement rather than an afterthought. The combination of high automation incentive and high accountability pressure makes exchanges early, serious adopters.
Conclusion
The phrase "AI agents" has been flattened by a thousand demos into something that sounds easy. Multi-agent systems architecture is the part nobody demos: the orchestration, the knowledge layer, the governance, and the design work that decides whether your agents fail safe or fail loud. OKX is paying senior-architect rates for it because at exchange scale, that gap between demo and production is the entire job.
If you're a senior engineer who's been treating agents as a toy, look again. The skills that make you good at this — distributed systems, failure design, the discipline to build for the moment things break — are exactly the ones you already have. The frameworks are learnable in months. The judgment took you years. That combination is what this role is actually hiring for, and there aren't many people who have both yet.